ESP32-P4 Deep Learning Tutorial: MNIST mit PyTorch und ESP-DL
Das Thema Machine Learning fasziniert mich schon seit einigen Jahren, aber mein Wissen darüber war bisher eher oberflächlich. Um wirklich zu verstehen, wie diese faszinierende Technologie funktioniert, habe ich mich nun etwas intensiver in diese Materie eingearbeitet. Mein Fokus lag dabei speziell auf Deep Learning, das auf künstlichen neuronalen Netzen mit vielen Schichten basiert.
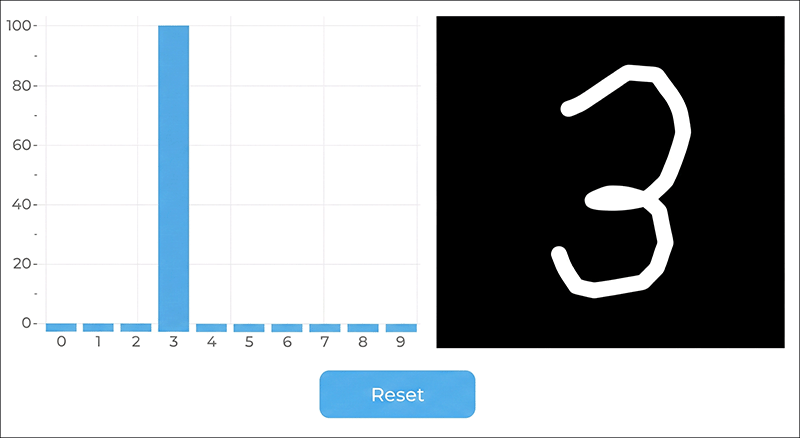
In diesem Artikel zeige ich das "Hello World" des Machine Learnings: die automatische Erkennung handgeschriebener Ziffern. Dieser Beitrag ist aber keine Einführung in die Grundlagen der Künstlichen Intelligenz, da dieses Themenfeld viel zu umfangreich ist. Stattdessen möchte ich anhand eines konkreten Beispiels alle notwendigen Schritte, vom Trainieren des neuronalen Netzes in Python (PyTorch) über die Quantisierung bis hin zur Live-Anwendung des fertigen Modells zeigen. Das Training des Modells erfolgt auf einem PC, verwendet wird das Netzwerk dann auf einem ESP32-P4 mit Display. Dazu verwende ich das CrowPanel Advance 7" ESP32-P4 HMI AI Display, das ich kürzlich vorgestellt habe.
Der Software-Stack: PyTorch und ESP-DL
Ein Machine-Learning-Projekt für Mikrocontroller teilt sich grundsätzlich in zwei Teile auf. Die rechenintensive Trainingsphase auf dem PC und die Ausführungsphase (Inferenz) auf dem Chip.
PyTorch als Trainingsumgebung
Für das Training verwende ich PyTorch, eines der führenden quelloffenen Deep-Learning-Frameworks. Es ermöglicht die schnelle Berechnung von mehrdimensionalen Matrizen auf der GPU und übernimmt die gesamte komplexe Mathematik für das Anpassen der Netzgewichte automatisch im Hintergrund.
Für die Datenseite übernehmen Dataset und DataLoader das Mischen, Batching und parallele Vorausladen der Trainingsdaten. In diesem Projekt laden sie den MNIST-Datensatz gemeinsam mit eigenen handgezeichneten Ziffern, die 50-fach gewichtet werden, damit die wenigen eigenen Bilder gegenüber den 60.000 MNIST-Samples nicht untergehen.
ESP-DL und ESP-PPQ
Das Espressif Deep Learning Framework (ESP-DL) bietet optimierte C++-Bibliotheken, die speziell dafür entwickelt wurden, neuronale Netzwerke effizient auf dem ESP32-P4 auszuführen. Hardwareseitig wird diese Software auf dem ESP32-P4 (sowie dem ESP32-S3) durch die Processor Instruction Extensions (PIE) massiv beschleunigt. Diese Befehlssatzerweiterung nutzt das SIMD-Prinzip (Single Instruction Multiple Data) und verarbeitet Daten hochparallel über dedizierte, 128-Bit breite Vektor-Register, die sogenannten Q-Register des Prozessors.
Das Bindeglied zwischen PyTorch (Python) und ESP-DL (C++) ist ESP-PPQ (Post-Training Quantization). Dieses Framework nimmt das PyTorch-Modell, komprimiert es von 32-Bit-Fließkommazahlen auf 8-Bit-Ganzzahlen (Int8) und wandelt es in eine .espdl-Datei um. Durch diese 8-Bit-Quantisierung passen exakt 16 Parameter des neuronalen Netzes gleichzeitig in ein einziges 128-Bit-Register des ESP32-P4. Der Mikrocontroller kann dadurch 16 Multiplikationen für die Faltungsschichten in einer einzigen Instruktion parallel ausführen.
Die Datenbasis: MNIST und eigene Bilder
Die Grundlage jedes Machine-Learning-Projekts sind die Trainingsdaten. Für die Ziffernerkennung gibt es den sogenannten MNIST-Datensatz, der 60.000 Trainingsbilder sowie 10.000 Testbilder von handgeschriebenen Ziffern enthält. Jedes Bild liegt im Format 28x28 Pixel in Graustufen vor und zeigt eine zentrierte Ziffer.

Grundsätzlich würde MNIST für diese einfache Demo völlig ausreichen, aber die Ziffern stammen vorwiegend aus dem amerikanischen Raum, wo es einige feine Unterschiede zu europäischen Ziffern gibt. Eine amerikanische "1" ist ein einzelner senkrechter Strich, eine europäische "1" hat einen markanten Aufstrich. Eine amerikanische "7" besteht aus zwei Strichen, die europäische Variante hat zusätzlich einen Querstrich in der Mitte. Durch diesen Dataset Bias würde das neuronale Netz eine typische europäische "1" mit Aufstrich als eine amerikanische "7" interpretieren und es kommt zu Fehlklassifikationen.
Daher habe ich im Freundeskreis mit einem Tablet möglichst viele Schriftproben erstellt und dann mit einem Python Script das Bild automatisch in die einzelnen Ziffern zerschneiden lassen.
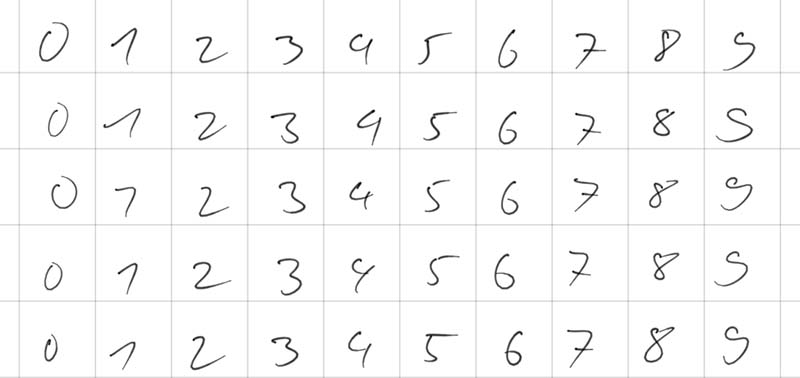
Würde man diese eigenen Bilder nun einfach den 60.000 MNIST-Bildern hinzufügen, gingen sie in der großen Masse völlig unter. Daher wird ein Konzept namens Oversampling (oder Datensatz-Boosting) angewendet. Die Bilder werden beim Laden in den Arbeitsspeicher per Code vervielfacht, damit sie während des Trainings ausreichend Relevanz erhalten.
Zusätzlich werden die Trainingsdaten bei jedem Ladevorgang künstlich verändert. Dieser Prozess nennt sich Data Augmentation. Über die PyTorch-Bibliothek transforms werden zwei zufällige Störfaktoren auf jedes Bild angewendet:
- Random Rotation: Das Bild wird zufällig um bis zu 10 Grad nach links oder rechts gedreht.
- Random Affine (Translation): Das Bild wird zufällig um bis zu 10 Prozent auf der X- oder Y-Achse verschoben.
Durch dieses "Wackeln und Verschieben" sieht das Netzwerk in jeder Trainingsepoche eine leicht abgewandelte Version derselben Ziffer. Das zwingt das Modell, die grundlegende Form der Ziffer zu erlernen, anstatt sich auf exakte Pixel-Koordinaten zu verlassen.
Der letzte sehr wichtige Vorverarbeitungsschritt ist die Normalisierung. Graustufenbilder bestehen normalerweise aus Pixelwerten zwischen 0 und 255. In PyTorch werden diese zunächst in Tensoren mit Werten zwischen 0.0 und 1.0 umgewandelt. Künstliche neuronale Netze trainieren jedoch am schnellsten und stabilsten, wenn die Eingabedaten um den Nullpunkt zentriert sind. Daher wird die Operation Normalize((0.1307,), (0.3081,)) angewendet, was der globale Mittelwert (0.1307) und die Standardabweichung (0.3081) des gesamten MNIST-Datensatzes ist.
Die Architektur des Convolutional Neural Networks
In der Bilderkennung werden oft sogenannte Convolutional Neural Networks eingesetzt. Daher habe ich auch für dieses Projekt auf diesen Netzwerktyp gesetzt. Da dieses Netzwerk später auch auf einem ESP32-P4 laufen muss, ist es sehr einfach konzipiert und hält sich weitgehend an die Beispiele, die man oft für den MNIST Datensatz findet.
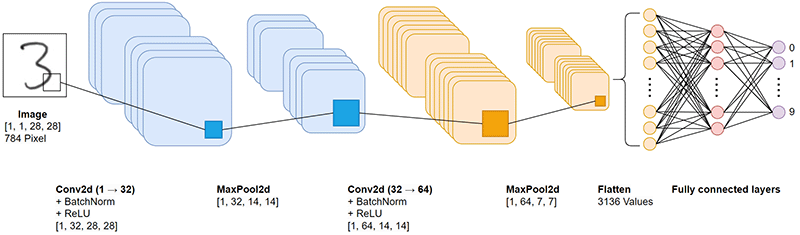
Da es der zentrale Teil des ganzen Projekts ist, möchte ich hier noch etwas genauer auf die einzelnen Schichten eingehen. Das CNN teilt sich konzeptionell in zwei Hauptphasen auf:
- Feature Extraction (Merkmalserkennung): Zwei Convolutional Blocks, die schrittweise abstrakte Bildmerkmale extrahieren, von simplen Kanten bis zu komplexen Bögen.
- Classification Head (Klassifikationskopf): Zwei Fully Connected Layers, die aus diesen extrahierten Merkmalen ableiten, um welche Ziffer es sich handelt
Ein Bild existiert im Speicher als mehrdimensionale Matrix (Tensor). Die Eingabe über das Touch-Display liefert dem Netz einen Tensor mit der Dimension [1, 1, 28, 28].
- 1 Bild (die Batch-Size, bei der Inferenz auf dem Mikrocontroller wird immer nur ein einzelnes Bild verarbeitet).
- 1 Farbkanal (Graustufen, RGB-Farbinformationen werden nicht benötigt).
- 28 Pixel Höhe.
- 28 Pixel Breite.
Jeder der 784 Pixel (28×28) hat einen Fließkommawert. Durch die vorgeschaltete Normalisierung im Python-Skript sind diese Werte um einen Mittelwert zentriert (z. B. zwischen -1.0 und +1.0). Diese 784 Werte bilden die Informationsgrundlage für das Modell.
Low-Level Merkmalserkennung
Die Faltung (Conv2d)
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
Die Faltung (Convolution) bildet das Fundament der Merkmalsextraktion. Dabei gleitet ein 3x3 Pixel großer Filter (der Kernel) schrittweise über das gesamte Bild. An jeder Position werden die Werte des Filters mit den darunterliegenden Bildpixeln multipliziert und aufsummiert.
Das Entscheidende dabei ist, dass die Werte innerhalb dieser Filter nicht vorprogrammiert, sondern durch den Trainingsprozess erlernt werden. Der Parameter out_channels=32 definiert, dass das Netz parallel 32 verschiedene Filter erlernt. Jeder Filter spezialisiert sich auf ein spezifisches Merkmal, beispielsweise auf vertikale Kanten oder diagonale Linien.
- kernel_size=3: Ein 3x3 Filter stellt einen etablierten Standard in der Bildverarbeitung dar. Er ist groß genug zur Mustererkennung, aber klein genug für hohe Recheneffizienz.
- padding=1: Ohne Padding würde das Bild nach der Faltung schrumpfen (von 28x28 auf 26x26). Das Padding fügt einen unsichtbaren Rahmen aus Nullen um das Bild hinzu, sodass die Ausgabe bei exakt 28x28 Pixeln verbleibt. Ein Informationsverlust an den Rändern wird so vermieden.
Die Parameteranzahl dieser Schicht berechnet sich wie folgt: 1 (Input-Kanal) × 32 (Filter) × 3 × 3 (Kernel-Größe) + 32 (Bias-Werte) = 320 Parameter.
Batch Normalization (BatchNorm2d)
self.bn1 = nn.BatchNorm2d(32)
Beim Datenfluss durch tiefe Netze entsteht oft das Phänomen des Internal Covariate Shift. Nach einer Gewichtsaktualisierung in der ersten Schicht verändert sich die Werteverteilung drastisch, was die nachfolgenden Schichten destabilisiert.
Batch Normalization löst dieses Problem, indem es die Aktivierungen jedes der 32 Kanäle zentriert und skaliert. Der Trainingsprozess wird dadurch erheblich stabilisiert und die Konvergenz beschleunigt.
Die Aktivierungsfunktion: ReLU
x = F.relu(x)
Nach der Faltung durchlaufen die Werte die ReLU-Funktion (Rectified Linear Unit): f(x) = max(0, x). Negative Werte werden auf Null gesetzt, positive Werte bleiben erhalten. Diese nicht-lineare Transformation ist zwingend erforderlich. Ein Netz ohne Nicht-Linearität lässt sich mathematisch auf eine einzige lineare Gleichung reduzieren und könnte keine komplexen, nicht-linearen Entscheidungsgrenzen erlernen.
Datenreduktion: MaxPooling
self.pool = nn.MaxPool2d(2, 2)
x = self.pool(x)
Ein 2x2 Pixel großes Fenster gleitet mit einer Schrittweite von 2 über die 32 Feature-Maps. Dabei wird immer nur der maximale Wert beibehalten, die restlichen Werte werden verworfen.
Das halbiert die räumliche Auflösung von 28x28 auf 14x14 Pixel und bietet zwei Vorteile:
- Rechenleistung: Die Datenlast für die kommenden Schichten wird um 75 % reduziert.
- Translationsinvarianz: Kleine räumliche Verschiebungen eines Merkmals spielen nun keine Rolle mehr. Das Maximum-Pooling fängt diese Unschärfen ab, wodurch das Netz robuster gegenüber Variationen in der Handschrift wird.
High-Level Merkmalserkennung
Der zweite Block arbeitet nach denselben Prinzipien, verarbeitet jedoch Daten auf einer höheren Abstraktionsebene. Die Eingabe besteht nicht mehr aus rohen Pixeln, sondern aus den 32 Merkmalskarten aus Block 1.
Die Anzahl der Filter wird auf 64 verdoppelt. Auf dieser Ebene kombiniert das Netz die einfachen Kanten aus dem ersten Block zu komplexeren Konstrukten wie Kreisbögen, Kreuzungen oder Schlaufen. Da die Anzahl der möglichen Kombinationen höher ist, werden mehr Filter benötigt.
Die Parameteranzahl dieser Schicht: 32 (In) × 64 (Out) × 3 × 3 (Kernel) + 64 (Bias) = 18.496 Parameter. Nach dem Durchlauf dieses Blocks und einem weiteren MaxPooling-Schritt ist die Auflösung auf 7x7 Pixel geschrumpft. Das Resultat sind 64 hochkonzentrierte, semantische Matrizen.
Flattening & Dropout
x = x.view(-1, 64 * 7 * 7)
self.dropout = nn.Dropout(0.5)
Flattening
Die finalen Klassifikations-Layer erfordern einen flachen, eindimensionalen Vektor. Mit der Funktion view werden die 64 Karten mit je 7x7 Pixel zu einem durchgehenden Vektor transformiert: 64 × 7 × 7 = 3.136 Werte. Das Bild wurde somit in einen numerischen "Fingerabdruck" aus 3.136 Merkmalen übersetzt.
Dropout
Ein bekanntes Problem bei tiefen neuronalen Netzen ist Overfitting, das unerwünschte Auswendiglernen der exakten Trainingsdaten anstelle der zugrundeliegenden Muster. Um dies zu verhindern, wird Dropout eingesetzt. Während des Trainings werden bei jedem Forward-Pass zufällig 50 % (p=0.5) der Verbindungen deaktiviert. Dies zwingt die Architektur zum Aufbau robuster Redundanzen und verhindert die Co-Adaptation einzelner Neuronen. Bei der Inferenz ist Dropout vollständig deaktiviert.
Classification Head
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
Die "Fully Connected" (Dense) Layers übernehmen die finale Klassifikation. Der Layer fc1 verbindet jedes der 3.136 Merkmale mit 128 neuen Neuronen. Parameteranzahl: 3136 × 128 + 128 = 401.536 Parameter. Mehr als 90 % der gesamten Modellparameter befinden sich in dieser einen Matrix-Multiplikation. Diese 128 Neuronen aggregieren die Informationen und erlernen, welche geometrischen Kombinationen für welche Ziffern charakteristisch sind.
Nach einer letzten ReLU-Aktivierung reduziert fc2 diese 128 Signale auf exakt 10 Ausgabewerte (Logits) für die Ziffern 0 bis 9.
Insgesamt umfasst das Modell ca. 421.642 trainierbare Parameter. Eigentlich eine recht hohe Zahl für so eine einfache Aufgabe. Zumindest bis man sich bewusst macht, dass aktuelle Sprachmodelle inzwischen über eine Billion Parameter besitzen.
Das Training: Implementierung in PyTorch
Das Training wird typischerweise in zwei getrennte Funktionen unterteilt: die Trainingsschleife und die Validierungsschleife.
Der Trainingszyklus (Forward und Backward Pass)
Die Funktion train ist das Herzstück des maschinellen Lernens. Hier passen sich die über 420.000 Parameter des Netzwerks iterativ an, um Ziffern korrekt zu identifizieren.
Zunächst wird das PyTorch-Modell mit der Funktion model.train() in den Trainingsmodus versetzt. Dropout beginnt nun, zufällig Verbindungen zu kappen, und BatchNorm berechnet die Mittelwerte für den aktuellen Batch. Anschließend wird der train_loader durchlaufen, der die Bilder in Batches (z. B. 64 Bilder gleichzeitig) auf den Prozessor oder die Grafikkarte lädt. Der eigentliche Lernschritt in der Schleife besteht aus vier fundamentalen Operationen:
optimizer.zero_grad()(Reset): Bevor neue Berechnungen angestellt werden, müssen die alten Gradienten (Steigungswerte) aus dem vorherigen Durchlauf auf Null gesetzt werden. Andernfalls würde PyTorch sie kontinuierlich aufaddieren, was das Training sofort zerstören würde.output = model(data)(Forward Pass): Die 64 Eingabebilder fließen durch das Netz. Das Resultat sind 64 Vektoren mit je 10 rohen Ausgabewerten (Logits).loss = F.cross_entropy(...)(Fehlerberechnung): Hier wird die Vorhersage des Netzes mit dem tatsächlichen Label (der echten Ziffer) verglichen. Die Kreuzentropie-Funktion (Cross-Entropy Loss) ist der mathematische Goldstandard für Klassifikationsprobleme. Sie bestraft das Modell besonders hart, wenn es sich bei einer falschen Vorhersage extrem sicher ist.loss.backward()undoptimizer.step()(Lernen): Durch Backpropagation berechnet PyTorch, wie stark jeder einzelne Parameter im Netz zu dem gemessenen Fehler beigetragen hat. Der Optimizer (in diesem Projekt der Adam-Optimizer) nimmt diese Informationen und passt die Gewichte minimal an, um den Fehler im nächsten Durchlauf zu verringern. Dieser Prozess entspricht einem iterativen Gradientenabstieg.
Die Validierung
Um zu überprüfen, ob das Modell die Ziffern wirklich lernt und nicht nur auswendig lernt (Overfitting), wird nach jeder Trainingsepoche die Funktion test aufgerufen. Sie nutzt den separaten test_loader, der 10.000 Bilder enthält, die das Netz zuvor noch nie gesehen hat.
Hier wird das Modell mit model.eval() in den Inferenzmodus geschaltet. Dropout wird deaktiviert, sodass nun 100 % der Neuronen aktiv sind. BatchNorm greift dadurch auf die gelernten, globalen Durchschnittswerte zurück. Da in der Testphase keine Gewichte mehr angepasst werden, wird die Berechnung mit with torch.no_grad() abgeschaltet.
Die Konsolenausgabe zeigt den Verlauf des Lernprozesses. Schon in Epoche 5 überschreitet das Modell die 99 %-Marke bei den unbekannten Testbildern:
Train Epoche: 1 [...] Loss: 0.177625 Test set: Average loss: 0.0673, Accuracy: 9760/10000 (97.60%) ... Train Epoche: 5 [...] Loss: 0.123470 Test set: Average loss: 0.0327, Accuracy: 9901/10000 (99.01%) ... Train Epoche: 29 [...] Loss: 0.069147 Test set: Average loss: 0.0177, Accuracy: 9946/10000 (99.46%)
Hier lässt sich auch sehr gut erkennen, ob ein Modell an sogenanntem Overfitting leidet. Würde der Loss-Wert der train-Schleife stetig weiter Richtung 0 sinken, während der Average loss der test-Schleife plötzlich wieder ansteigt, würde das Modell beginnen, die Trainingsdaten nur noch auswendig zu lernen.
In diesem Trainingslauf ist das jedoch nicht der Fall. Der Fehler der Testdaten stabilisiert sich auf einem sehr niedrigen Niveau, ohne wieder signifikant anzusteigen. Dies beweist, dass die implementierten Gegenmaßnahmen, insbesondere Dropout und die dynamische Data Augmentation durch Verschieben und Drehen der Bilder, perfekt funktionieren und das Modell robust generalisiert. Das Modell erreicht seinen Bestwert in Epoche 29 mit einer Genauigkeit von 99,46 %.
Quantisierung: Das Modell für den ESP32-P4 vorbereiten
Das trainierte PyTorch Modell arbeitet mit 32-Bit Fließkommazahlen. Damit der ESP32-P4 dieses Modell verwenden kann, müssen die Modellparameter in 8-Bit oder 16-Bit Ganzzahlen konvertiert werden. Für ein einfaches MNIST Modell reicht das kompakte Int8 Format völlig aus. Dadurch kann der Hardwarebeschleuniger des ESP32-P4 über das SIMD-Prinzip 16 Int8-Werte in einer einzigen Instruktion parallel verarbeiten, was die Inferenz massiv beschleunigt.
Der ONNX-Export
Zunächst wird das Modell über einen Dummy-Eingabetensor in das ONNX-Format konvertiert. ONNX (Open Neural Network Exchange) ist ein offenes, von Microsoft, Meta und AWS entwickeltes Format, das den Austausch von Deep-Learning- und Machine-Learning-Modellen zwischen unterschiedlichen Frameworks erlaubt. Wichtig ist dabei der Parameter do_constant_folding=True. Er integriert statische Berechnungen wie die Batch-Normalisierung direkt in die Faltungsgewichte. Das befreit das Netzwerk von überflüssigen Rechenknoten und beschleunigt die spätere Ausführung auf dem Mikrocontroller spürbar.
Kalibrierung und Quantisierung mit esp_ppq
Für die Umwandlung von 32-Bit-Fließkommazahlen auf 8-Bit-Ganzzahlen übernimmt das Post-Training-Quantization-Framework von Espressif (esp_ppq). Um die optimale Skalierung zu ermitteln, führt der Quantizer eine Kalibrierung durch. Dazu werden 32 echte Bilder aus dem Testdatensatz an die API übergeben.
Mit dem ONNX-Modell und diesen Kalibrierungsbildern generiert die Funktion quantize_onnx_model für die Zielarchitektur TargetPlatform.ESPDL_INT8 das quantisierte Netzwerk. Abschließend erzeugt export_ppq_graph die fertige .espdl-Datei, die vom ESP32-P4 verarbeitet werden kann.
Deployment auf dem ESP32-P4: Inferenz in C++
Im letzten Schritt wird das trainierte und quantisierte Modell auf dem Mikrocontroller ausgeführt. Als Zielplattform verwende ich das CrowPanel Advance 7" ESP32-P4 HMI AI Display. Dieses Board bietet sowohl die nötige Rechenleistung als auch ein gutes Touchpanel für die Eingabe der Ziffern.

Um das Modell live zu testen, habe ich eine einfache Applikation entwickelt. Sobald man beginnt, eine Ziffer auf das Panel zeichnet, berechnet das Netzwerk in Echtzeit die Wahrscheinlichkeitswerte und stellt diese direkt als Balkendiagramm dar.
Softwarestruktur und Benutzeroberfläche
Die Benutzeroberfläche habe ich mit EEZ-Studio erstellt. Sie besteht nur aus drei Teilen, dem Balkenchart, ein Canvas zum Zeichnen und der Reset Button.
Die gesamte Projektstruktur sieht wie folgt aus:
ESP32-MNIST-Demo/ │ ├── build/ │ ├── eez-studio/ (EEZ Studio Project) │ ├── main/ │ ├── display/ (MIPI DSI Display) │ │ ├── display.c │ │ └── display.h │ ├── gui/ (LVGL Canvas & Chart) │ │ ├── canvas_paint.c │ │ ├── canvas_paint.h │ │ ├── chart_display.c │ │ └── chart_display.h │ ├── mnist/ (Model Inference Code) │ │ ├── mnist_inference.cpp │ │ ├── mnist_inference.h │ │ ├── mnist_task.c │ │ └── mnist_task.h │ ├── ui/ (EEZ-Studio generated Code) │ │ ├── actions.h │ │ ├── fonts.h │ │ ├── images.c │ │ ├── images.h │ │ ├── screens.c │ │ ├── screens.h │ │ ├── structs.h │ │ ├── styles.c │ │ ├── styles.h │ │ ├── ui.c │ │ ├── ui.h │ │ └── vars.h │ ├── CMakeLists.txt │ ├── idf_component.yml │ └── main.c │ ├── managed_components/ (Used Components) │ ├── espressif__cmake_utilities/ │ ├── espressif__dl_fft/ │ ├── espressif__esp-dl/ │ ├── espressif__esp-dsp/ │ ├── espressif__esp_lcd_ek79007/ │ ├── espressif__esp_lcd_touch/ │ ├── espressif__esp_lcd_touch_gt911/ │ ├── espressif__esp_lvgl_port/ │ ├── espressif__esp_new_jpeg/ │ └── lvgl__lvgl/ │ └── spiffs/ (PyTorch generated Model) └── mnist_advanced_cnn.espdl
Das Projekt wurde mit Visual Studio Code und dem ESP-IDF Plugin von Espressif erstellt.
Das Modell im Flashspeicher: SPIFFS und Partitions
Damit der Mikrocontroller das neuronale Netz laden kann, wird die generierte ESPDL Datei im ESP32 Projekt in einen Ordner namens spiffs gelegt. Beim Upload des Projekts über den ESP-IDF Plugin wird der Inhalt direkt in den Flashspeicher des ESP32-P4 geschrieben. Dafür muss zwingend die Datei partitions.csv angepasst werden, um dem SPIFFS Dateisystem ausreichend Speicherplatz (mindestens die Größe der Modelldatei) einzuräumen:
# ESP-IDF Partition Table # Name, Type, SubType, Offset, Size, Flags # Note: if you have increased the bootloader size, make sure to update the offsets to avoid overlap nvs, data, nvs, , 0x4000, otadata, data, ota, , 0x2000, phy_init, data, phy, , 0x1000, factory, app, factory, , 0x3F0000, ota_0, app, ota_0, , 0x3F0000, ota_1, app, ota_1, , 0x3F0000, model, data, spiffs, , 0x3F0000,
Beim Systemstart wird dieses Dateisystem im C++ Code eingehängt (gemountet) und das Modell über die Klasse dl::Model direkt in den Arbeitsspeicher geladen:
bool mnist_inference_init(void) { /* Mount SPIFFS with model file */ esp_vfs_spiffs_conf_t spiffs_conf = { .base_path = "/model", .partition_label = "model", .max_files = 2, .format_if_mount_failed = false, }; esp_err_t ret = esp_vfs_spiffs_register(&spiffs_conf); if (ret != ESP_OK) { ESP_LOGE(TAG, "SPIFFS mount failed: %s", esp_err_to_name(ret)); return false; } /* Load model */ ESP_LOGI(TAG, "Loading model..."); model = new dl::Model("/model/mnist_advanced_cnn.espdl", fbs::MODEL_LOCATION_IN_SDCARD); ESP_LOGI(TAG, "Model loaded."); return true; }
Neben SPIFFS unterstützt ESP-DL auch das Laden des Modells von SD-Karte oder das Einbetten des Modells in den Binärcode der Applikation.
Hardwarebeschleunigte Skalierung mit dem PPA
Das neuronale Netz erwartet exakt das Format der Trainingsdaten, also ein 28x28 Pixel großes Graustufenbild. Das Displays hat jedoch eine Auflösung von 1024x600 Pixel und die Zeichenfläche (Canvas) hat eine Größe von 448x448 Pixeln. Diese Größe ist bewusst so gewählt, da sich 448 ohne Rundungsfehler durch 16 teilen lässt (28 mal 16 = 448).
Würde der Mikrocontroller dieses große Bild bei jeder Touch Eingabe per Software herunterskalieren, käme es zu merklichen Verzögerungen beim Zeichnen. Hier kommt der integrierte Pixel Processing Accelerator (PPA) des ESP32-P4 zum Einsatz. Über den SRM Block (Scale, Rotate, Mirror) des PPA wird das 448x448 RGB Bild komplett in Hardware um den Faktor 1/16 skaliert:
const uint8_t *ppa_resize(void) { ppa_srm_oper_config_t srm_cfg = { .in = { .buffer = canvas_buf, .pic_w = CANVAS_WIDTH, .pic_h = CANVAS_HEIGHT, .block_w = CANVAS_WIDTH, .block_h = CANVAS_HEIGHT, .block_offset_x = 0, .block_offset_y = 0, .srm_cm = PPA_SRM_COLOR_MODE_RGB565, }, .out = { .buffer = srm_out_buf, .buffer_size = srm_out_buf_size, .pic_w = PPA_OUT_SIZE, .pic_h = PPA_OUT_SIZE, .block_offset_x = 0, .block_offset_y = 0, .srm_cm = PPA_SRM_COLOR_MODE_RGB565, }, .rotation_angle = PPA_SRM_ROTATION_ANGLE_0, .scale_x = PPA_SCALE_FACTOR, .scale_y = PPA_SCALE_FACTOR, .mode = PPA_TRANS_MODE_BLOCKING, }; esp_err_t ret = ppa_do_scale_rotate_mirror(ppa_srm_handle, &srm_cfg); if (ret != ESP_OK) { ESP_LOGE(TAG, "PPA SRM failed: %s", esp_err_to_name(ret)); memset(gray_buf, 0, sizeof(gray_buf)); return gray_buf; } // ... Convert RGB565 to grayscale ... return gray_buf; }
Der Mikrocontroller wird dadurch deutlich entlastet und muss das 28x28 Pixel Bild nur noch in Graustufen umwandeln.
Inferenz, Normalisierung und Quantisierungsmathematik
Bevor diese Graustufenbilder vom neuronalen Netzwerk verarbeitet werden, müssen sie genau so wie im Python Trainingsskript normalisiert werden (Mittelwert 0.1307 und Standardabweichung 0.3081). Da das Modell als 8 Bit Integer Netzwerk vorliegt, liefert die ESP-DL Bibliothek über input->get_exponent() den bei der Kalibrierung berechneten Skalierungsexponenten. Die normalisierten Fließkommazahlen werden mit diesem Exponenten multipliziert, gerundet und auf den gültigen Int8 Wertebereich (-128 bis 127) begrenzt.
Sobald die Bilddaten in den Eingabetensor geschrieben wurden, genügt ein Aufruf von model->run(). Dank der PIE Vektorbefehle dauert dieser Inferenzprozess nur etwa 20 Millisekunden. Anschließend werden die rohen Int8 Ausgabewerte (Logits) wieder in Fließkommazahlen zurückgewandelt:
bool mnist_inference_run(const uint8_t *gray_28x28, float scores[MNIST_NUM_CLASSES]) { if (!model) return false; dl::TensorBase *input = model->get_input(); dl::dtype_t input_dtype = input->get_dtype(); int input_exponent = input->get_exponent(); /* Int8 model: normalize then quantize with model's exponent */ float scale = powf(2.0f, (float)(-input_exponent)); int8_t *dst = (int8_t *)input->get_element_ptr(); for (int i = 0; i < 28 * 28; i++) { float pixel = gray_28x28[i] / 255.0f; float normalized = (pixel - MNIST_MEAN) / MNIST_STD; float quantized = roundf(normalized * scale); if (quantized > 127.0f) quantized = 127.0f; if (quantized < -128.0f) quantized = -128.0f; dst[i] = (int8_t)quantized; } /* Run inference */ model->run(); /* Read output scores */ dl::TensorBase *output = model->get_output(); int output_exponent = output->get_exponent(); dl::dtype_t output_dtype = output->get_dtype(); int num = output->get_size(); if (num > MNIST_NUM_CLASSES) num = MNIST_NUM_CLASSES; for (int i = 0; i < num; i++) { int8_t raw = output->get_element<int8_t>(i); scores[i] = (float)raw * powf(2.0f, (float)output_exponent); } return true; }
Die Datei chart_display.c bietet zwei Visualisierungsmodi für das Display, die über die Konstante CHART_MODE_RAW ausgewählt werden können.
Die erste Variante nutzt eine Softmax Funktion zur Umwandlung der Netzwerkausgaben in Wahrscheinlichkeiten. Durch die exponentielle Berechnung wird der jeweils höchste Einzelwert stark angehoben, während die restlichen Ausgaben bis zu Null fallen können. Der Fokus liegt dabei darauf, eine eindeutige Entscheidung für eine Ziffer zu treffen.
Die zweite Variante verwendet eine direkte Skalierung der Ausgabewerte. In diesem Modus bleiben die originalen Relationen der Vorhersage erhalten und die Balken zeigen die tatsächliche Gewichtung zueinander. Bei dieser Methode kann man sehr gut erkennen, wie sicher beziehungsweise unsicher die Werte des Netzwerks sind.
Live Demo: Das System in Aktion
Wie flüssig das neuronale ESP-DL Netzwerk mit dem ESP32-P4 funktioniert, zeigt das folgende kurze Demo Video. Die Ausgabe verwendet die direkte Skalierung:
Ich könnte stundenlang mit dem Display spielen, weil es total faszinierend ist, der künstlichen Intelligenz bei der Arbeit zuzusehen. Vor allem finde ich es sehr interessant, wie oft schon ein kleiner Strich ausreicht, um das Netzwerk umzustimmen, sodass die Wahrscheinlichkeit plötzlich von einer Ziffer zur nächsten springt.
Allerdings fallen beim Testen auch ein paar Eigenheiten auf. Bei Verwendung der Softmax Variante hat fast immer eine Ziffer 100 Prozent Wahrscheinlichkeit, auch wenn ganz offensichtlich keine Ziffer gezeichnet ist. Dieses Verhalten ist jedoch kein Fehler des Modells, sondern ein rein visuelles Phänomen dieser speziellen Funktion. Wechselt man zur direkten Skalierung der Ausgabewerte, verhält sich das System wie erwartet und zeigt bei unsinnigen Eingaben korrekterweise für alle Ziffern einen niedrigen Wert an.
Die zweite Eigenheit betrifft die Positionierung auf der Zeichenfläche. Für eine zuverlässige Vorhersage muss die Ziffer zentriert und relativ groß gezeichnet werden. Der Grund dafür liegt im Aufbau der verwendeten Trainingsdaten. Im originalen MNIST Datensatz sind alle Ziffern exakt in der Mitte des Bildes ausgerichtet und füllen den verfügbaren Platz fast vollständig aus. Zeichnet man nun eine kleine Zahl in eine äußere Ecke des Touchdisplays, wird die Ziffer meistens nicht erkannt.
Fazit
Ich habe recht lange an diesem Projekt gearbeitet, bis das System fehlerfrei funktionierte. Der Aufwand hat sich aber gelohnt, da ich bei der Entwicklung extrem viel gelernt habe. In der Praxis begreift man solche Konzepte wesentlich besser als durch reine Theorie aus Büchern. Ich hätte auch durchaus Ideen für sinnvolle Anwendungen zuhause, allerdings fehlt mir momentan schlichtweg eine Quelle für die passenden Trainingsdaten. Genau mit dieser Datengrundlage steht und fällt am Ende jedes Deep Learning Projekt. Der Python und C++ Code für das gesamte Projekt liegt zum Ausprobieren auf GitHub.